
CPU တစ်ခုချင်း၏ စွမ်းရည်မှာ လက်ရှိအချိန်အခါတွင် တိုးတက်နှုန်းမှာ ရပ်တန့်လာသည်ကို တွေ့ရပြီး၊ Multi Core CPU များကို တဖြည်းဖြည်း အသုံးပြုလာသည်ကို တွေ့ရပါသည်။ Java သည်လည်း ခေတ်နှင့် အညီ Multi Core အာကီတက်ချာများတွင် အသုံးဝင်သော ဆော့ဖ်ဝဲဒီဇိုင်းဖြစ်သော Parallel Programming ဘက်ကို အားစိုက်လာပါသည်။ Cloud Computing နှင့် VM Ware များအား အသုံးများလာသော ယနေ့အချိန်တွင် Parallel Programming ဘက်ကို ဦးတည်လာရခြင်းမှာ ခေတ်၏ လိုအပ်ချက်တစ်ခု ဖြစ်သောကြောင့် ဖြစ်ပါသည်။
ဒီလောက် အလားအလာရှိသော ပညာရပ်အား ဘာကြောင့် ရေးရင်းတန်းလန်း ရပ်ခဲ့ရသနည်း ဟုဆိုပါက အကြောင်း ၂ချက်ရှိပါသည်။ ထိုစဉ်က ကျွှန်တော်၏ ကွန်ပျုတာမှာ 32bit P4 Windows XP လေး ဖြစ်သောကြောင့်၊ Core များများကို အသုံးပြု၍ ရေးသားရသော အပလီများအား အသုံးပြုပါက ပို၍ လေးသွားသောကြောင့် Fork And Join ၏ အကျိုးအား လုံးလုံး မသိရှိနိုင်သောကြောင့် မတက်သာပဲ နားခဲ့ရပါသည်။ နောက်တစ်ချက်မှာ Fork And Join သည် အစက Project Lambda နှင့် တွဲ၍ Release လုပ်ရန်ရည်ရွယ်ထား၏။ Fork And Join အား ရေးရာတွင် Closure အား အသုံးမပြုပါက ထပ်ချည်းတလည်းလည်း ကုဒ်များအား ရေးရကိန်းရှိသောကြောင့် Closure နှင့် တွဲရေးရန် အစကတည်းက ပြင်ဆင်ထားခဲ့ကြ၏။ သို့သော်လည်း အကြောင်းကြောင်းကြောင့် Java 7 တွင် Closure အား ရေးသားနေသော Project Lambda အား Release မလုပ်နိုင်ခဲ့ကြ။ Java 8 ကျမှ Release လုပ်မည်ဟု ထုတ်ပြန်ခဲ့ကြ၏။ အဲ့လိုနဲ့ပဲ ကျွှန်တော်လည်း Fork And Join အား ဆက်မရေးပဲ ထားခဲ့ပါသည်။
ယခုဆိုလျှင် Java 7 သည်လည်း အတော်လေး အသားကျလာပြီး၊ Java 8 လည်း ထွက်ပါတော့မည်ဟု ဟန်ရေးတပြင်ပြင်လုပ်နေပြီ ဖြစ်သည်။ Fork And Join အား ဆက်လက် လေ့လာသွား ပါဦးမည်။ ယခုတစ်ခေါက်တွင်တော့ နောက်ကြောင်းပြန်သည့် အနေနှင့် မြန်မာအိုင်တီပရိုတွင် ရေးသားခဲ့သည်များကို ပြန်လည် ဖော်ပြပါဦးမည်။
Concurrency မှ Fork / Join ဆီသို့
Java သည် Version 1.0 ကို ထုတ်ပြန်ထားသည့် အချိန်ကတည်းက Thread များကို အသုံးပြုနိုင်ခဲ့၏။ ကျွှန်တော်ကိုယ်တိုင်လည်း ထိုစဉ်အခါက C နှင့် Basic များကို သာအသုံးပြုခဲ့ဘူးပါသဖြင့်၊ Thread တစ်ခုအလုပ်လုပ်နေစဉ် အခြားသော Thread တစ်ခုအား နောက်ကွယ်တွင် အလုပ်ခိုင်း ထားနိုင်ခြင်း အပေါ်တွင် လွန်စွာမှ အံ့သြမိခဲ့၏။
သို့ရာတွင် Thread များကိုအသုံးပြုရာတွင် အခန့်မသင့်ပါက Dead Lock များကို ဖြစ်ပွားစေတတ်ခြင်း၊ Data များကို ပျက်စီးစေတတ်ခြင်း အစရှိသည့် မလိုလားအပ်သော ပြဿနာများကိုလည်း ဖြစ်ပေါ်စေနိုင်ပါသည်။ လွယ်လင့်တကူ အသုံးပြုနိုင်သော်လည်း၊ ကျွမ်းကျင်စွာအသုံးပြုနိုင်ရန် Parallel Processing နှင့်ပတ်သက်သော အသိပညာများကိုလည်း နားလည်ထားရန် လိုအပ်ခဲ့ပါသည်။
အထက်ပါ အကြောင်းအရင်းများကြောင့် Parallel Processing ကို ပို၍လွယ်ကူစွာအသုံးပြုနိုင်ရန် Parallel Processing Framework တစ်ခုဖြစ်သော Concurrency Utilities ကို Java SE 5 တွင် ထည့်သွင်းခဲ့၏။ Concurrency Utilities တွင် Asynchronous Processing API၊ Thread Save လုပ်ပြီးအသုံးပြုနိုင်သော အဆင့်မြင့် Parallel Processing သုံး Collection များ၊ Lock Mechanism နှင့် Atomic Processing အစရှိသည့် Parallel Processing တွင် အသုံးပြုနိုင်သော နည်းပညာများကို အသုံးပြုလာနိုင်စေခဲ့၏။
Concurrency Utilities တွင် Asynchronous Processing များကို အသုံးပြုရာတွင် Executor Interface မှတဆင့် အသုံးပြုနိုင်၏။ တဖန် Thread Pool ကိုလည်း အဆင်သင့်အသုံးပြုနိုင်ရန် ပြင်ဆင်တား၏။ အဲ့ဒီအတွက် Thread Class ကို တိုက်ရိုက်ဆက်သွယ်ရန် မလိုအပ်သောကြောင့် Parallel Processing ကို အသုံးပြုရန်မှာ အရင်ကလောက် ခက်ခဲခြင်းမရှိတော့ပါ။
သို့ရာတွင် Concurrency Utilities ထွက်ပေါ်ပြီးတဲ့နောက်မှာ Hardware ၏ ဖွဲ့စည်းပုံမှာလည်း လွန်စွာမှပြောင်းလည်းခဲ့ပေသည်။ Java SE 5 ထွက်ပေါ်ခဲ့သည့် 2004 ခုနှစ်နောက်ပိုင်းတွင် CPU တစ်လုံးချင်း၏ Clock အရေအတွက်မှာ ထင်သလောက် တိုးတက်ခြင်းကို မမြင်တွေ့ရတော့ပဲ Multi Core Architecture ဘက်ကို ပြောင်းလာခဲ့ပါသည်။ လက်ရှိ အချိန်တွင် အိမ်သုံးကွန်ပျူတာများ မှာတင် အနည်းဆုံး 4 Core အသုံးပြုလာနိုင်ပြီး၊ Server များမှာဆိုလျှင် သည့်ထက်ပို၍များပေမည်။ ဤကဲ့သို့ CPU ၏ ဖွဲ့စည်းပုံပြောင်းလည်းမှု့အပေါ်မှုအပေါ်တွင် Software များဘက်မှ အပြည့်အဝ အသုံးပြုနိုင်ခြင်းမရှိသေးပါ။ တနည်းဆိုသော် အသစ်ပြောင်းလည်းလာသော CPU ၏ ဖွဲ့စည်းပုံနှင့် ကိုက်ညီသော Software များကို ပြင်ဆင်ထားရန် လိုအပ်လာခဲ့ပါသည်။ အဲ့ဒီအတွက် တတ်နိုင်သလောက် Process များကို ခွဲပြီး၊ CPU ၏ Core များကို ညီညီမျှမျှခိုင်းစေရန် လိုအပ်လာခဲ့ပါသည်။
ပြဿနာက ဤနေရာမှစတင်ပါတော့သည်။ Concurrency Utilities ၏ Executor မှာ သေးငယ်သော Process များကို အလုပ်လုပ်စေရာတွင် မကိုက်ညီသောအချက်ပင်ဖြစ်၏။ Executor မှာ လေးလံသော Process များကို အလုပ်လုပ်စေရာမှာ ထူးချွံသော်လည်း၊ သေးငယ်သော Process များကို အလုပ်လုပ်စေရာမှာ မလိုလားအပ်သော Overhead များကိုဖြစ်ပေါ်စေပါသဖြင့် Performance ကို ကျဆင်းစေတတ်ပါသည်။ ဤနေရာတွင် ထွက်ပေါ်လာသည်က Java SE 7 တွင် ပါဝင်ရန် ပြင်ဆင်ထားသော Fork /Join Framework ပဲ ဖြစ်ပါသည်။
Concurrency Utilities သည် JCP ၏ JSR 166 ဖြင့် ဖွဲ့စည်းပုံနည်းပညာများကို သတ်မှတ်ရေးသားခဲ့၏။ Fork / Join Framework သည်လည်း JSR အသစ်ကိုပြုလုပ်ခြင်းမရှိပဲ JSR 166 ကို ပြုပြင်ရေးသားခြင်းအားဖြင့် နည်းပညာများကို သတ်မှတ်ရေးသားလျှက် ရှိ၏။ Concurrency Utilities နှင့် Fork / Join Framework ကို ခွဲခြားနိုင်ရန်၊ Fork / Join Framework ကို JSR 166y ဟု ခေါ်ဆိုလေ့ရှိ၏။ JSR 166y သည်လည်း JSR 166 နှင့်အတူ Mr Doug Lea မှ ဦးစီး၍ ရေးသားလျှက်ရှိပါသည်။
Divide And Conquer Alogrithm
Multi Core CPU များ၏ စွမ်းအားများကို အပြည့်အဝအသုံးချနိုင်ရန် Task များကို တတ်နိုင်သလောက် သေးငယ်အောင် စိတ်ပိုင်းပြီး၊ core အားလုံးကို မျှတစွာ အလုပ်လုပ်ခိုင်းဖို့ လိုအပ်သည် ဟုဖော်ပြခဲ့ပါသည်။ Task များကို စိတ်ပိုင်းရာတွင် လူသိများသည့်နည်းလမ်းမှာ Quick Sort နှင့် Merge Sort Algorithm တွင် အသုံးပြုထားသော Divide And Conquer Algorithm ပဲဖြစ်ပါသည်။

D&C တွင် ပြဿနာတစ်ခုကို ဖြေရှင်းရာတွင်၊ အားလုံးကို တစ်ပြိုင်နက်တည်း ဖြေရှင်းရာ၌ လွန်စွာခက်ခဲနေပါက၊ အစိတ်စိတ်အပိုင်းပိုင်းခွဲ၍ အကြိမ်ကြိမ်ဖြေရှင်း သွားသည့်နည်းလမ်းကို အသုံးပြုပါသည်။ ခွဲစိတ်ထားသော ပြဿနာက ဖြေရှင်းနိုင်လောက်သည့်ပမာဏ လောက်ကိုရောက်သောအခါမ တိုက်ရိုက်ဖြေရှင်းခြင်း ဖြစ်၏။ D&C Algorithm ကို Java ဖြင့် ရေးကြည့်ပါမည်။
Result solve(Problem problem) {
if (problem ကိုဖြေရှင်းနိုင်သည်) {
problem ကို တိုက်ရိုက်ဖြေရှင်းမည်;
return ရလဒ်;
} else {
problem ကို problem1 နှင့် problem2 အဖြစ် စိတ်ပိုင်းပါမည်;
Result result1 = solve(problem1);
Result result2 = solve(problem2);
result1 နှင့် result2 ကို ပူးပေါင်းမည်;
return ပူးပေါင်းထားသော ရလဒ်;
}
}
အကြိမ်ကြိမ် ခွဲကာဖြေရှင်းနေခြင်းပင် ဖြစ်၏။ လုပ်ဆောင်ချက် တစ်ခုကို အကြိမ်ကြိမ်ပြန်လည် အသုံးပြုနေပါသဖြင့် Performance မှာ အားနည်းပါလိမ့်မည်။ ထို့အတွက် Single Thread ကိုအသုံးပြု၍ ဖြေရှင်းလိုပါက အကြိမ်ကြိမ်ပြန်လည် ခေါ်ယူနေသောနေရာကို Loop အဖြစ်ပြောင်းလည်းခြင်း အစရှိသည့် ပြုပြင်ချက်များကို ပြုလုပ်ရန်လိုအပ်ပါသည်။ သို့ရာတွင် အကြိမ်ကြိမ်ခွဲခြားခေါ်ယူခြင်းကို Multi Core များတွင် ခွဲခြားအလုပ်လုပ်စေမည် ဆိုပါက CPU တစ်ခုထဲတွင် အလုပ်လုပ်စေခြင်း မဟုတ်သည့်အတွက် လွန်စွာမှသင့်တော်မည့် နည်းလမ်းဖြစ်ပါသည်။
ကျွှန်တော်တို့ နမှုနာတစ်ခုအဖြစ် အီတလီသင်္ချာပညာရှင် Fibonacci ၏ Fibonacci Number မေးခွန်းတစ်ခုကို ဖြေရှင်းကြည့်ပါမည်။
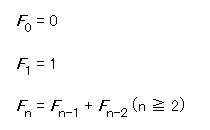
Fibo.java
public class Fibo {
int n =0;
public Fibo(int n) {
this.n = n;
}
public int compute() {
if(n <= 1)
return n;
Fibo f1 = new Fibo(n-1);
Fibo f2 = new Fibo(n-2);
return f1.compute() + f2.compute();
}
public static void main(String [] args) {
int inter = new Fibo(40).compute();
System.out.print(inter);
}
}
အထက်ပါ Fibo Class တွင် private field အနေနဲ့ int n ကို ပိုင်ဆိုင်ပါတယ်။ တဖန် Constructor မှာလည်း Argument အနေရဲ့ int n ကို ရယူပြီး၊ private field ကို အစားထိုးနေပါသည်။ compute လုပ်ဆောင်ချက်တွင်လည်း n ၏ တန်ဖိုးက 1 ဒါမှမဟုတ် 1 ထက်ငယ်ပါက n ကို return လုပ်မည်ဖြစ်၏။ သို့မဟုတ်ပါက f1 နှင့် f2 instance ကို new လုပ်ပြီး၊ အသီးသီး တန်ဖိုးကိုရှာပြီး ရလဒ်ကိုပေါင်း၍ return လုပ်မည် ဖြစ်၏။အထက်ပါ Fibo Class ကို Fork / Join Framework ကို အသုံးပြု၍ ရေးသားကြည့်မည် ဆိုပါက အောက်ပါအတိုင်းရေးသားနိုင်မည် ဖြစ်၏။
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class FiboTask extends RecursiveTask<Integer> {
private final int n;
public FiboTask(int n) {
this.n = n;
}
@Override
protected Integer compute() {
if(n <= 1)
return n;
FiboTask f1 = new FiboTask(n-1);
f1.fork();
FiboTask f2 = new FiboTask(n-2);
return f2.compute() + f1.join();
}
public static void main(String [] args) {
int result = new ForkJoinPool(Runtime.getRuntime().
availableProcessors()).invoke(new FiboTask(40));
System.out.println(result);
}
}
Fork / Join Framework ကို အသုံးပြုရန်အတွက် Process များကို ခွဲရန် RecursiveTask ကို အမွေဆက်ခံရန် လိုအပ်ပါသည်။ တဖန် RecursiveTask ၏ အမွေခံ Class များသည် compute လုပ်ဆောင်ချက်ကို Override လုပ်ရန်လိုအပ်ပေသည်။ အတွင်းပိုင်းတွင်မှု n သည် 1 ထက်ကြီးပါက n-1 နှင့် n-2 ကို ခွဲပြီး FiboTask ဖြင့် တန်ဖိုးကို ပြန်ရှာပါသည်။အထက်ပါ ကုဒ်များထဲတွင် f2 မှာ အကြိမ်ကြိမ်ပြန်ခေါ်ခြင်းဖြင့် တန်ဖိုးကို ရှာဖွေနေပါသော်လည်း f1 မှာမူ fork လုပ်ဆောင်ချက်ကို အသုံးပြု၍ Asynchronous Task အဖြစ်ခွဲခြားပြီး အလုပ်လုပ်စေပါသည်။ ပြီးဆုံးကာမှ join လုပ်ဆောင်ချက်ဖြင့် ရလဒ်ကို ပြန်လက်ခံနေပါသည်။နောက်ဆုံးတွင် f1 နှင့် f2 တို့၏ ရလဒ်များကို ပြန်ပေါင်း၍ ပြန်ပို့နေခြင်း ဖြစ်၏။ RecursiveTask ကို ခေါ်ယူအသုံးပြုရာတွင် ForkJoinPoll မှတဆင့်ခေါ်ယူရပါသည်။ ဦးစွာ Runtime#availableProcessors ဖြင့် အသုံးပြုနိုင်သော Processer အရေအတွက်ဖြင့် ForkJoinPoll ၏instance ကို ခေါ်ယူပါသည်။ ပြီးပါက ForkJoinPool#invoke ဖြင့် FiboTaskကို အလုပ်လုပ်ခိုင်းနေခြင်းသာပင်ဖြစ်၏။
Before Running Program

Running Program

JDK7 ဖြင့် ကွန်ပိုင်းလုပ်ပြီး၊ အလုပ်လုပ်ခိုင်းကြည့်သော အခါ အထက်ပါအတိုင်း ဖော်ပြနိုင်သည်ကို တွေ့ရပါမည်။ အထက်ပါ နမှုနာတွင်လည်း တွေ့ခဲ့ကြရသလို Fork / Join Framework သည် Processor များများနှင့် Parallel Processing များကို အလုပ်လုပ်စေရာတွင် အသုံးပြုနိုင်ရန် ပြင်ဆင်ထားသော Framework တစ်ခုဖြစ်ပါသည်။
လေးစားစွာဖြင့်။
မင်းလွင်
This design is steller! You most certainly know how
ReplyDeleteto keep a reader amused. Between your wit and your videos, I was almost moved to start my own blog (well,
almost...HaHa!) Fantastic job. I really loved what you had to say, and more than that, how you presented it.
Too cool!
Fantastic beat ! I wish to apprentice while you amend your
ReplyDeleteweb site, how could i subscribe for a blog website? The account aided me a appropriate deal.
I had been a little bit familiar of this your broadcast provided vivid
clear idea
I think this is among the most vital info for me. And i'm glad reading your article.
ReplyDeleteBut want to remark on some general things, The website style is great, the articles
is really nice : D. Good job, cheers
This article provides clear idea for the new visitors of blogging,
ReplyDeletethat actually how to do blogging and site-building.
Wonderful goods from you, man. I've understand your stuff
ReplyDeleteprevious to and you're just too wonderful. I really like what you've acquired here, certainly like what you are stating and the way in which you say it.
You make it enjoyable and you still take care of to
keep it sensible. I can not wait to read far more from you.
This is actually a wonderful website.
I go to see everyday a few web sites and information sites to read articles, except this weblog provides
ReplyDeletequality based content.
This info is worth everyone's attention. Where can I find out
ReplyDeletemore?
Hello There. I found your weblog the usage of msn. That is a really smartly written article.
ReplyDeleteI'll be sure to bookmark it and come back to read more of your useful information. Thanks for the post.
I will definitely comeback.
Undeniably believe that which you said. Your
ReplyDeletefavorite justification seemed to be on the net the easiest thing to be
aware of. I say to you, I certainly get annoyed while people
consider worries that they plainly do not know about.
You managed to hit the nail upon the top and also
defined out the whole thing without having side-effects ,
people could take a signal. Will likely be back to get more.
Thanks
It's a shame you don't have a donate button! I'd certainly donate
ReplyDeleteto this fantastic blog! I guess for now i'll settle for book-marking and
adding your RSS feed to my Google account. I look forward to
brand new updates and will share this blog with my Facebook group.
Chat soon!